
视觉问答的分层共同注意
Lesion-Aware Transformers for Diabetic Retinopathy Grading
文献原文 Lesion-Aware Transformers for Diabetic Retinopathy Grading
1 | @INPROCEEDINGS{9578017, author={Sun, Rui and Li, Yihao and Zhang, Tianzhu and Mao, Zhendong and Wu, Feng and Zhang, Yongdong}, booktitle={2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, title={Lesion-Aware Transformers for Diabetic Retinopathy Grading}, year={2021}, volume={}, number={}, pages={10933-10942}, doi={10.1109/CVPR46437.2021.01079}} |
文章正在研究的问题
Diabetic Retinopathy Grading 即糖尿病视网膜病变分级。作为糖尿病引发的血管损伤最严重的并发症之一,糖尿病视网膜病变是导致上班人群永久失明的一大主要原因。使用机器进行自动的糖尿病视网膜病变诊断可以帮助专家诊治病人,其主要包括两个方面:病变的分级(DR grading)和病变区域的发现(lesion discovery)。分级按照国际标准可以分为五个等级:正常(normal)、轻微(mild)、中等(moderate)、严重非增值性(severe non-proliferative)、增值性(proliferative)。可以用二分类的方法来处理它们,如no DR(normal) vs DR(abnormal)、non-referable(normal and mild) vs referable(可转诊的)(worse)。
主要贡献
动机
目前大多数已有的方法是将病变分级和病变区域发现作为两个独立的任务来处理,在这个过程中需要病变区域的标注作为指导。然而,病变区域的标注是很困难的,需要专业人士的同时又需要标注大量的数据,才能满足监督学习的需要,这就造成这些方法在实际的部署落实的过程中受到限制。因此一种弱监督方案,即只需要分级标注数据就可以学习并同时进行分级和病变区域发现的模型(MICCAI2017),是非常有必要的。然而,之前提出的此类方法没有考虑到数据bias(偏差)的问题,即模型总是过分的关注于最重要的一些病变区域,而忽略了一些零星的病变区域,这些零星的区域有可能对最终的分级产生影响。因此有必要检测出全部的病变区域,并对这些区域进行一个重要性的评估。
基于此目标,作者考虑以下三个方面:1.病变区域的分布通常是相对稀疏的(左图),假如将病变区域进行放大,可以发现在一个病变区域内,病变部分的像素级特征是相似的,而与背景部分是有较大差异的(中图)。因此有必要对像素相关性进行建模,以实现稳健的特征学习;2.并不是所有的病变区域都对最后的分级会有影响,甚至有些区域是噪声,因此需要自适应的训练每一个区域的重要度权重;3.即使两张眼底照片的分级相同,它们的病变区域和类型也并不一定相同,分级的判断往往不是由某一个区域决定的,而是需要联合周围的病变区域才能做出最后的判断(右图)。
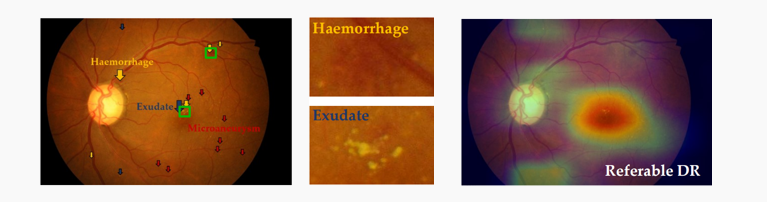
工作
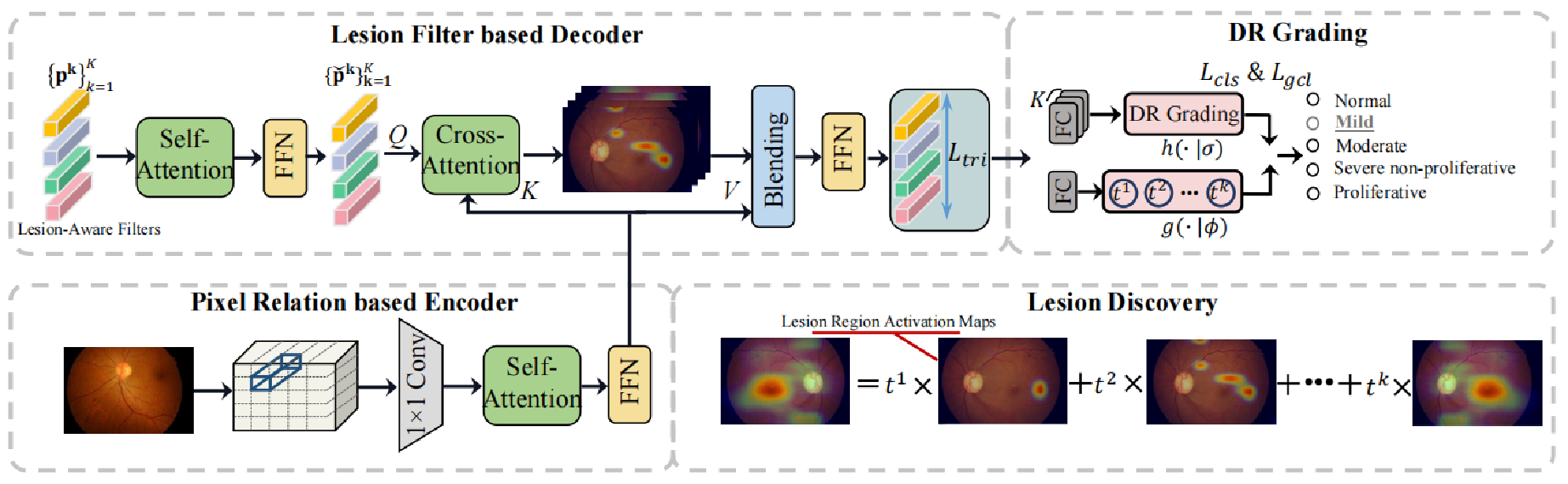
基于上述的三点发现,作者提出了一种基于病变感知的transformer结构。网络的输入是一张眼底图片,每一张图片都有病变分级的标签,但没有病变区域的标注。通过某一种backbone网络(如resnet50)来提取出特征图,然后经过设计的网络,输出一个预测的分级类别和与之对应的病变激活图。网络整体可以分为3个部分,分别是:Encoder部分,Decoder部分,和预测部分。
- Encoder部分预测像素级别的关系,该部分的输入为一张经过backbone网络后的特征图,之后经过self-attention结构得到一张聚合了上下文信息的增强特征图。
- Decoder部分的初始输入为一系列滤波器和Encoder部分的输出,每一个滤波器是一个向量,经过self-attention结构来聚合滤波器之间的上下文信息,之后将此作为cross-attention中的query,然后用Encoder的输出作为key和value,去寻找每一个滤波器所对应的病变区域,最后混合输出,得到病变区域感知的特征。
- 预测部分作者设计了3个损失函数,分别是用于对比学习的triplet loss,常规的cross entropy loss,以及全局一致性损失。triplet loss主要拉近相同分级的特征,然后增加不同分级的特征的差异性;cross entropy loss则是常规的多分类交叉熵损失;全局一致性损失是通过每一个mini-batch的结果不断更新特定分级类别的中心特征,然后在每一个batch中将该batch得到的中心特征向全局中心特征靠拢,从而达到增加不同分级类别的差异性,并有助于分类。
方案
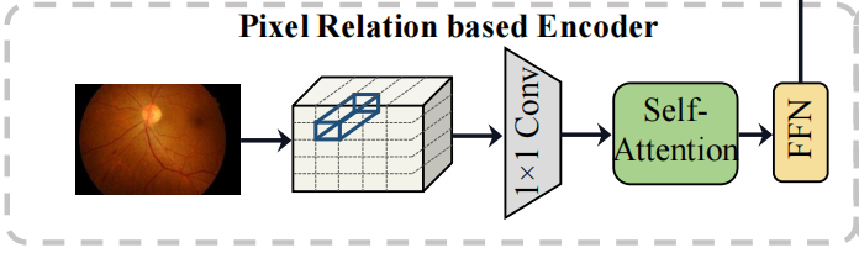
首先是encoder部分,该部分的作用主要是生成像素级别的关系表达,捕捉全局的上下文信息。
具体步骤:首先将backbone输出的特征图通过一个1*1的卷积网络降低网络的通道数,之后再将图片进行拉伸成二维矩阵模式,从而适配transformer结构。之后采用multi-head(实验中使用8个)的self-attention结构,去自适应的学习不同区域的attention权重S,并得到每一个head的输出Hn。转换矩阵的映射维度设置成L/8是为了将得到的每一个head进行拼接后维度可以恢复成L,并得到最后的表达H。之后通过一个FFN(两个全连接网络)来得到最后的feature map。在这里,通过self-attention环节,能够收集具有相似外观的病变区域的像素,有效的抑制了因曝光不足或过度,失焦等问题造成的背景像素混乱的问题。
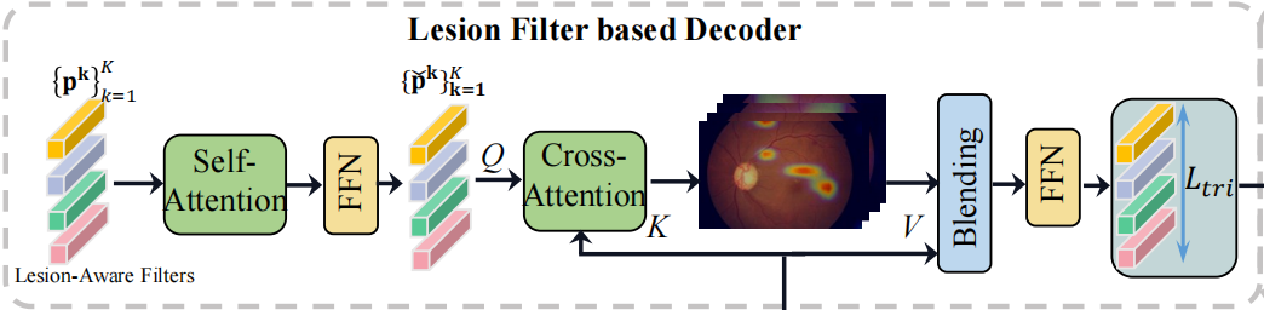
其次是decoder部分,该部分的主要作用为识别不同的病变区域。
主要步骤:首先初始化一些 病变区域滤波器(lesion filter),每一个滤波器是一个L维的向量,总共有K个,组合起来就是K×L维,之后通过一个与encoder模块的self-attention+FFN相同的结构,这样,通过充分融合上下文信息,可以得到更具有差异性的滤波器表达。并将其作为cross-attention模块的query,key和value为encoder模块的输出。这样,通过计算attention权重,我们可以得到一个K×HW维度的Sn矩阵,通过对每一个head取平均,可以得到一张病变区域感知的激活图,K即为滤波器的个数,将HW恢复成二维即可以得到原尺寸。这样,每一个滤波器都有它所对应的激活图,权重高的地方就代表该滤波器所指的病变区域。之后将S与value矩阵相乘,就可以得到病变区域感知的特征向量X。
当然,由于没有病变区域的数据标注,因此就很难有效的去训练病变感知的特征。作者设计了两种机制来约束病变区域特征的生成。
一、病变区域重要性学习机制:利用一个全连接层(g)来将每一个病变特征映射到一个值,这个值即代表该特征的重要性权重,之后通过一个sigmoid激活函数将权重限制在[0,1]。通过这个环节,可以有效地减少不利病变信息对于特定DR水平的影响。
二、病变区域多样性学习机制:该部分采用对比学习的方式,其triplet loss的每一个anchor为每一个filter生成的病变区域特征,对比的范围为每一个mini-batch,其中m即为batch中的图片编号,k为该滤波器的编号标签。由于没有病变区域的标签,因此做不到对病变区域的特征进行直接的对比学习,退而求其次,可以根据图片的分级标签,让分级相同的图片中相同编号的滤波器能够生成一个相似的特征,分级不同的图片中相同编号的滤波器生成特征具有差异性。其具体过程为:d+表示相同分级标签的不同图片的余弦相似度中的最小值(余弦相似度越大,则特征越相似,该部分的目的就是找出标签相同中最不相似的一对特征,然后训练使得它们相似);d-表示不同分级标签的不同图片的余弦相似度中的最大值(该部分作用与d+相反,即让不同标签的特征最相似的一对特征变得不相似)。最后将mini-batch中的所有区域的损失都加起来作为该batch的损失值,其中T为一个batch中的图片数,K为滤波器的个数(即预设病变区域的个数)。

上一步得到了病变区域的特征,并对这些特征做了一个重要性的权重训练,接下来就是根据这些特征进行图片级别的病变分级。由于上一步中有K个滤波器,因此得到的病变特征也有K个,因此,该模块的开始,作者设计了K个全连接层(h)来分别对它们进行分类,得到y,其中C表示类别的数量。之后,将上面计算得到的每一个病变区域的权重与之相乘,并累加K个滤波器即可得到一张眼底图片的最终分类结果,该结果与真值标签z比较可得到多分类交叉熵损失Lcls。
另外,每一个mini-batch在训练过程中,我们都可以得到每一个分级类别的中心特征,计算方式为:将属于c类的图片全部取出,然后将其中的每一个病变区域的特征与其权重相乘,然后做一个平均。每一个类别的中心特征是一个向量,在每个batch中我们都可以得到若干类别的中心特征,为了让不同batch训练得到的特定类别的中心特征更加的相似,作者额外维护了一个全局特征b,在每一个batch训练后,都会对其进行更新,其中的tc代表在过去在训练中已经出现过的c类的图片的数量。最后作者通过L2损失来保证每个类别中心特征的全局一致性。因此,网络的整体包括3个损失函数,多分类交叉熵损失,对比损失,和全局一致性损失,其中的λ是权重参数,在实验中分别被设为0.04和0.01。另外,通过对Decoder中得到的每一张病变区域感知的激活图进行重要性权重的加权累加,我们可以得到最后的融合激活图,该图就可以代表该眼底照片中的病变区域分布。
思考
实验复现发现,图片预处理对结果影响也挺大,如原始图片周围背景黑框等,可能占有很大部分,合适的裁剪和mask方法,可以一定程度上提高预测准确率。天文图像与此应用场景有相通的地方,如太阳活动预报中核心关键的部分可能只占很小一部分,可以使用此方法迁移试试。