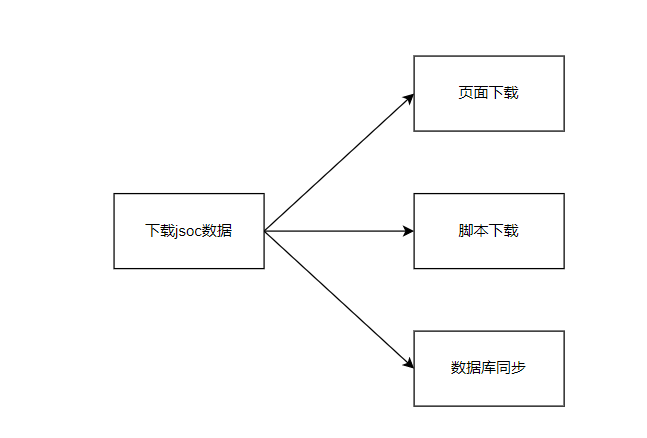
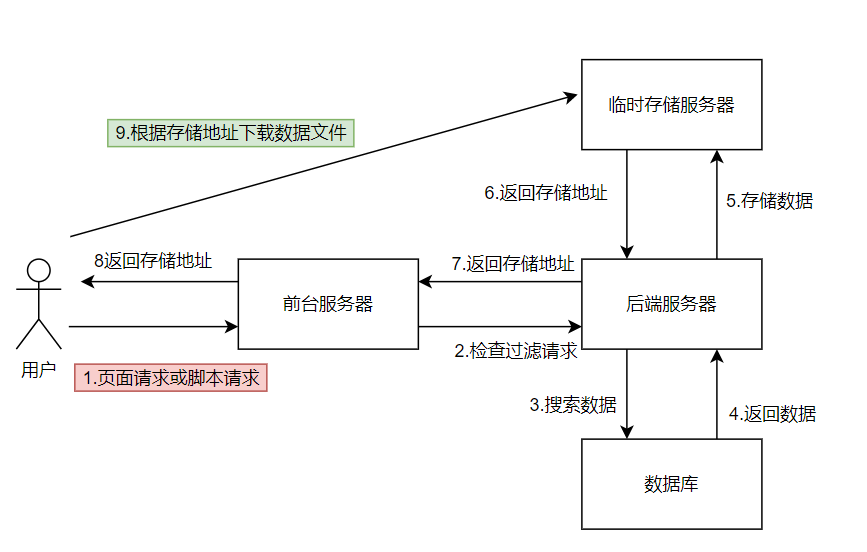
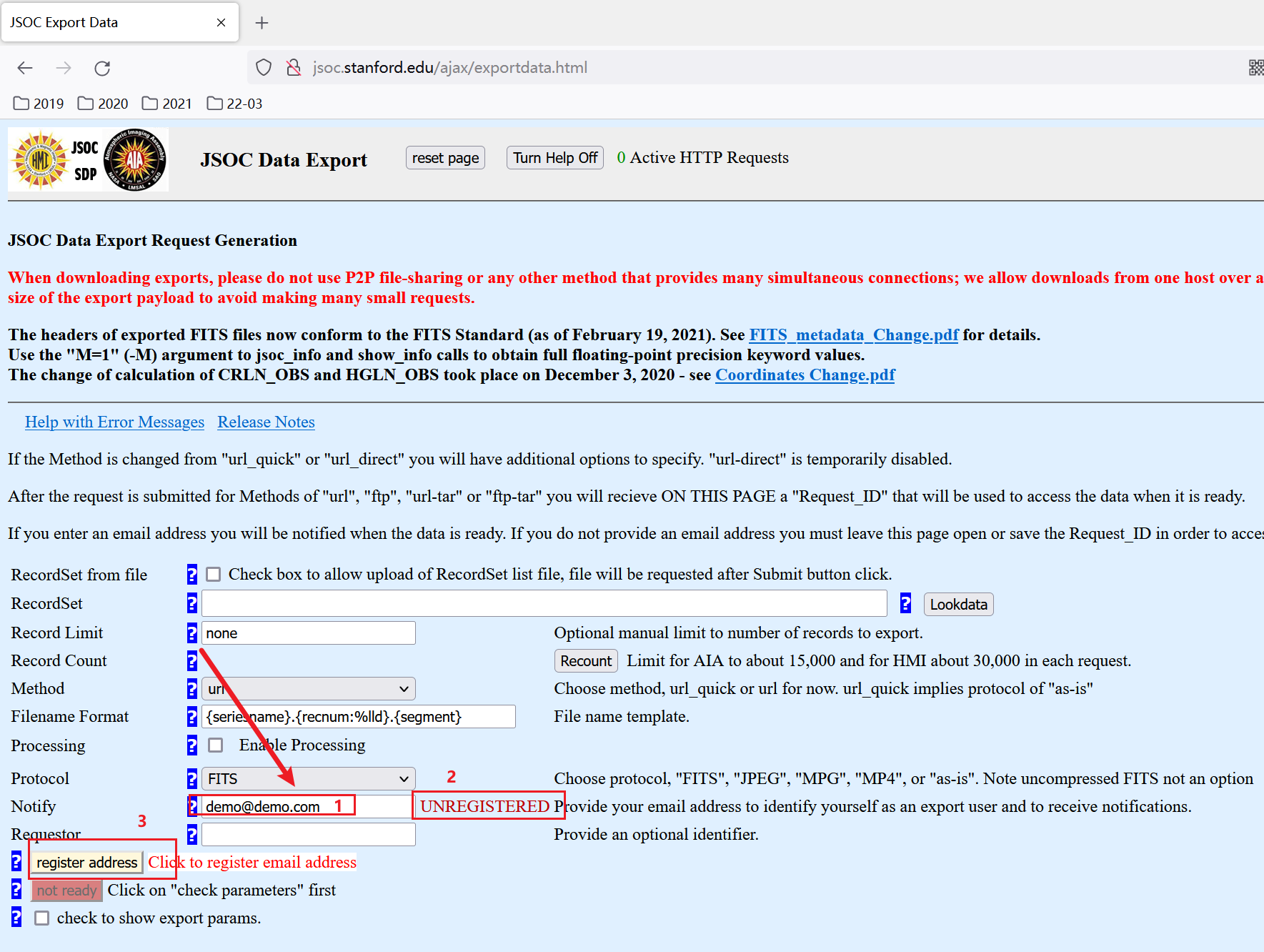
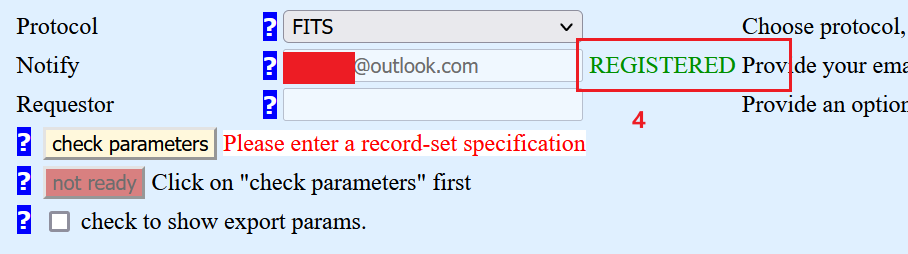
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
|
"""
Purpose: [1] download data Bp Bt Br from jsoc
[2] Demonstrate sunpy for jsoc basic usage,
Officially already has a good package, this is just a demonstration of basic use
Usage: This code depends on the requests bs4 lxml zeep drms sunpy astropy
They can be installed from conda or pip
This code is compatible with python 3.7.x.
Examples: None Now
Adapted: ZhaoZhongRui (zhaozhongrui21@mails.ucas.ac.cn) Edit Python code From Thomas Wiegelmann (2022.03)
"""
from sunpy.net import Fido, attrs as a
import astropy.units as u
from concurrent.futures import ProcessPoolExecutor
import os
class DownloadJsoc():
def __init__(self):
self.is_print_log = True
self.mail_address_list = []
self.data_save_root_path = None
def download_one_by_time_point(self, timepoint, harpnum, email=None, save_path=None):
"""
Download the file based on the point in time
:param timepoint: eg "2010-01-01T00:00:00.000"
:param harpnum: eg "220"
:param email: eg "eg@eg.com" register at http://jsoc.stanford.edu/ajax/exportdata.html
:param save_path: str path
:return: None
"""
result = False
try:
if email is None:
if isinstance(self.mail_address_list, list) and len(self.mail_address_list) > 0:
email = self.mail_address_list[0]
if save_path is None:
if os.path.exists(self.data_save_root_path):
save_path = self.data_save_root_path
search_tuple = (
a.Time(timepoint, timepoint),
a.jsoc.Series("hmi.sharp_cea_720s"),
a.jsoc.Notify(email),
a.jsoc.Segment("Bp"),
a.jsoc.Segment("Bt"),
a.jsoc.Segment("Br"),
a.jsoc.PrimeKey("HARPNUM", str(harpnum)),
)
results = Fido.search(*search_tuple)
downloaded_files = Fido.fetch(results, path=save_path)
result = downloaded_files
except BaseException as e:
print(e)
return result
def download_one_by_time_range(self, timestart, timeend, harpnum, timedelta=96, email=None, save_path=None):
"""
download by time range and delta
:param timestart: str eg "2010-01-01T00:00:00.000"
:param timeend: str eg "2022-01-01T00:00:00.000"
:param harpnum: str eg "235"
:param timedelta: int eg 96
:param email: str eg "eg@eg.com"
:param save_path: str path which to save file
:return: result set or False
"""
result = False
try:
if email is None:
if isinstance(self.mail_address_list, list) and len(self.mail_address_list) > 0:
email = self.mail_address_list[0]
if save_path is None:
if os.path.exists(self.data_save_root_path):
save_path = self.data_save_root_path
search_tuple = (
a.Time(timestart, timeend),
a.jsoc.Series("hmi.sharp_cea_720s"),
a.jsoc.Notify(email),
a.jsoc.Segment("Bp"),
a.jsoc.Segment("Bt"),
a.jsoc.Segment("Br"),
a.jsoc.PrimeKey("HARPNUM", str(harpnum)),
a.Sample(timedelta * u.min),
)
results = Fido.search(*search_tuple)
downloaded_files = Fido.fetch(results, path=save_path)
result = downloaded_files
except BaseException as e:
print(e)
return result
def __download_one_by_time_point_concurrent(self, timepoint, harpnum, job_num=0, save_path=None):
print('job num: {} / pid : {} is runing\n'.format(job_num, os.getpid()))
email_len = len(self.mail_address_list)
mail_num = job_num % email_len
result = self.download_one_by_time_point(timepoint, harpnum, self.mail_address_list[mail_num], save_path)
return result
def download_some_by_time_point(self, timepoint_list, harpnum_list):
"""
:param timepoint_list:
:param harpnum_list:
:return:
"""
result = []
t_len = len(timepoint_list)
h_len = len(harpnum_list)
if t_len == h_len:
for i in range(t_len):
this_result = self.download_one_by_time_point(timepoint_list[i], harpnum_list[i])
result.append(this_result)
return result
def download_some_by_time_point_concurrent(self, timepoint_list, harpnum_list):
"""
Give a list of times and numbers to download data in parallel,Note that the two dimensions should be consistent
:param timepoint_list: eg ["2018-09-08T14:24:00.000","2018-09-08T00:00:00.000"]
:param harpnum_list: eg ["7020","7020"]
:return: None
"""
result = []
t_len = len(timepoint_list)
h_len = len(harpnum_list)
if t_len == h_len:
max_workers = len(self.mail_address_list)
executor = ProcessPoolExecutor(max_workers=max_workers)
for i in range(t_len):
future = executor.submit(
self.__download_one_by_time_point_concurrent,
timepoint_list[i],
harpnum_list[i],
i)
result.append(future)
executor.shutdown(True)
def tran_json_file_tai_num_time_to_download_format(self, raw_str):
"""
Convert the file time downloaded by json to the parameter time required for download,
eg "7020.20170524_222400_TAI" to ["7020","2018-09-08T14:24:00.000"]
Both in the list are in str format
:param raw_str: str, eg "7020.20170524_222400_TAI"
:return: [ str, str ] -> [ harpnum , timestr ], eg ["7020","2018-09-08T14:24:00.000"],
If the over-feed value is malformed, the conversion fails and is returned None,
"""
result = None
if isinstance(raw_str, str):
str_list = raw_str.split(".")
if len(str_list) == 2:
if len(str_list[1]) >= 15:
try:
hnum = int(str_list[0])
this_list = str_list[1]
stime = "20{}-{}-{}T{}:{}:00.000".format(
this_list[2:4],
this_list[4:6],
this_list[6:8],
this_list[9:11],
this_list[11:13],
)
result = [hnum, stime]
except BaseException as e:
print(e)
return result
def get_job_list_from_file(self, file_path):
"""
The file content is like "7020.20170524_000000_TAI\n7020.20170524_222400_TAI\n"
:param file_path: str or os.path format
:return: ["7020.20170524_000000_TAI","7020.20170524_222400_TAI"]
"""
result = []
if os.path.exists(file_path):
with open(file_path, "r") as f:
all_list = f.read().split("\n")
result = all_list
return result
def demo_download_one(self):
self.download_one_by_time_point("2018-08-23T17:36:00.000", "7300",email="eg@eg.com",save_path="/data")
def demo_download_some_from_file(self, file_path=None, save_path=None, mail_list=None):
"""
get work job from file and run concurrent
The file content is like "7020.20170524_000000_TAI\n7020.20170524_222400_TAI\n"
:param file_path: str or os.path format
:param save_path: the path to save file
:param mail_list: ["eg@eg.com","eg2@eg2.com"] which has registered in jsoc before
:return: None
"""
if file_path is None:
return False
if file_path is not None:
self.data_save_root_path = save_path
if mail_list is not None:
self.mail_address_list = mail_list
job_raw_list = self.get_job_list_from_file(file_path)
num_list = []
time_list = []
for job_raw in job_raw_list:
job_tran = self.tran_json_file_tai_num_time_to_download_format(job_raw)
if job_tran is not None:
num_list.append(job_tran[0])
time_list.append(job_tran[1])
self.download_some_by_time_point_concurrent(time_list, num_list)
if __name__ == "__main__":
print("start run")
d = DownloadJsoc()
file_path = r"/www/wwwroot/app_run/data/a"
save_path = r"/www/wwwroot/app_run/data"
mail_list = ["demo1@outlook.com",
"demo2@outlook.com",
"demo3@outlook.com",
"demo4@outlook.com", ]
d.demo_download_some_from_file(file_path, save_path, mail_list)
|