
LIME应用于模型解释
文献原文 “Why Should I Trust You?”: Explaining the Predictions of Any Classifier
1 | @inproceedings{10.1145/2939672.2939778, |
文章正在研究的问题
提出一种解释模型的方法,解释机器学习或深度学习得出的模型,使得人可以理解。
需求引入(为什么要解释器)
假设我们已经有了一个判断肿瘤的模型,但是这个模型可不可靠,它是根据什么进行判断和推测的,从而决定这个模型是否可以使用,以及其在实际生产中的角色,是可信的绝对依赖,还是有一定的参考价值,还是仅仅辅助参考。
即主要以下两个方面:
- 说服别人(建模型阶段)
- 这个模型判断的依据给展示出来,告诉模型建造者这个模型是可信的,
- 比如根据狗鼻子判断这个动物是狗。
- 工程意义(部署阶段)
- 将结果和输入建立更加丰富的关系,
- 比如以前只是输出60%的几率是狗,但是不知道它根据啥判断的,可以解释模型,让他把依据标出来,
- 比如标出狗鼻子和耳朵是判断60%的依据;比如判断文章是否违规,把文字标出来,是哪些文字导致违规。
比如,根据背景是雪判断动物是狼是不可靠的(原因是数据集里面大部分都是狼在雪,狗在家)

比如,文章分类中,分类“基督教”有关还是“无神论教”,发现结果准确率达到90%多,正常情况下是相信这个模型,但是通过解释发现,判断无神的文章中Posting(投稿邮件标头一部分)出现频率很高,就是说,他判断的依据是错的。

解释器的基础特征(什么是解释器)
身为一个解释器,文中要求至少满足以下特征:
- 可解释性(Interpretable)
- 局部忠诚(Local Fidelity)
- 与模型无关(Model-Agnostic)
- 全局视角(Global Perspective)
可解释性:包含两个部分,分别为模型和特征。我们以模型为例,像决策树或是线性回归都是很适合拿来解释的模型,前提是特征也要容易解释才行。所以利用可解释的模型配上可解释的特征,才是真正的可解释性。否则像是词嵌入(Word Embedding)的方式,即使是简单的线性回归也无法做到可解释性。而且解释性还要取决于目标群体,比如如何向不了解的机器学习的门外汉去解释这些模型。
为什么决策树或是线性回归是可以理解的,个人认为是因为,决策树这种一层层分下来和人的思维较为相似,线性这种哪些变量变化对结果影响较大,也有直观感受。
局部忠诚:既然我们已经使用了可解释的模型与特征,就不可能期望简单的可解释模型在效果上等同于复杂模型(比如原始CNN分类器)。所以解释器不需要在全局上达到复杂模型的效果,但至少在局部上效果要很接近,而此处的局部代表我们想观察的那个样本的周围。
与模型无关:这里所指的是与复杂模型无关,换句话说无论多复杂的模型,像是SVM或神经网络,该解释器都可以工作。
全局视角:从图2文章分类的案例中可以看出,准确度有时并不是一个很好的指标,所以我们才需要去解释模型。解释器的工作在于提供对样本的解释,来帮助人们对模型产生信任。
这里直接摘自链接:https://blog.csdn.net/evilhunter222/article/details/80043251
主要贡献
lime方法(怎么实现)
首先回忆下解释器的目的:“对于一个分类器(复杂模型),想用一个可解释的模型(简单模型如线性规划),搭配可解释的特征进行适配,并且这个可解释模型再局部的表现上很接近复杂模型的效果”。
LIME的全称为:Local Interpretable Model-Agnostic Explanation,中文字面上的意思就是与模型无关的局部可解释性的解释。
LIME通过扰动输入样本(perturb the input),来判断哪些特征的存在与否,对于输出结果有着最大的影响。而扰动的精髓在于这些绕扰动必须是人类可以理解的。像是一张图片中,将图片中的部分区域进行遮盖,对识别效果肯定是有一定影响的。
提出方案
数学理解角度
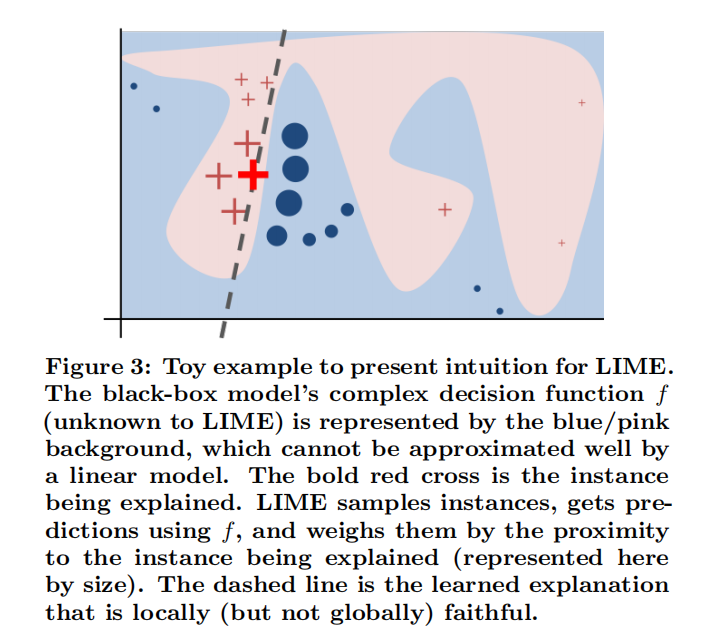
无论再复杂的模型都可以理解为是一个函数,函数再复杂,在局部都可以看成是线性的,类似高数中曲线无限放大,局部取极限可以看成是直线。
下图红和蓝区域表示一个复杂的黑盒分类模型,图中加粗的红色十字表示需要解释的样本。全局用一个可解释的模型(如线性模型和决策树)去逼近拟合它。如果只看局部,在某些局部是可以用线性模型去拟合的。
具体步骤:
- 1、在红色十字附近进行采样,即取和红色十字相似数据,即在红十字上改变一点点特征
- 2、将上面采样的数据代入分类器模型,得到结果,结果即红十字和蓝色点,同时根据红十字和蓝色点到原始红十字的距离决定权重,图中表现为大小
- 3、根据采样得出的结果即红十字和蓝色点,学到的局部线性可解释模型,即虚线,就是一个简单的线性分类器。
- 4、然后局部的线性模型就是人类可以理解的,线性可以理解表现为:哪些变量变化对结果影响大,哪些变量变化对结果影响小。
代码角度
编程伪代码角度

- 下图为LIME的伪代码过程:
- 1.首先要有一个好的分类器$f$(复杂模型)
- 2.选定一个要解释的样本$x$,以及在可解释维度上的$x’$
- 3.定义一个相似度计算方式,以及要选取的$K$特征来解释
- 4.进行$N$次扰动
- 5.$z_i’$:从$x’$扰动而来(可解释的扰动)
- 6.将$z’$还原到$d$维度,并计算预测值$f(z)$以及相似度
- 7.收集到$N$次扰动后的样本后,利用K-Lasso回归取得对这个样本有影响力的系数
编程软件包使用角度
官方给的demo很详细,大概过程是,
- 1、创建预测函数,即把调用模型封装成一个函数,
- 2、运行解释,即调用对应解释权进行解释,
- 3、对结果可视化。
https://github.com/marcotcr/lime/blob/master/doc/notebooks/Tutorial%20-%20images%20-%20Pytorch.ipynb
https://github.com/marcotcr/lime/blob/master/doc/notebooks/Submodular%20Pick%20examples.ipynb
我的想法
关于是否打开盒子
感觉lime本质上没有直接打开网络的盒子,就是用一个可以理解的函数模拟指定条件下的一种盒子,实现类比效果,并没法解释每一层在干什么,即类似医学影像处理的深度学习可解释性研究进展提到的中-端逻辑关系,如果将复杂模型理解为决策树,这个lime的local特性只是解释了一个分支。
关于数据集和模型适用性
lime模型解释是适用于复杂模型和简单模型的,本质上可以抽象成输入格式单一的函数就行,注意这里的输入格式单一指的是都是文本,或者都是图片,如果是多模态的模型是不易使用lime解释的。
关于结果粒度
官方给的notebook演示都是可以跑通的,实验复现发现考虑到运行效率,多个像素组成区域的“超像素”看作一个整体,即lime是粗粒度,对图像的标注的热力图是那种块状的,无自然过渡,而且增加解释样本点的数据量,对最终结果并没有太大影响,还是粒度比较粗。
关于其他作用
感觉在部署阶段还具有一定的探索意义,在已知领域进一步发展人的理论,在一些未知领域可能具有探索意义。
比如,根据肿瘤照片建模训练的模型,可以分类出哪些是肿瘤,把这些判断依据标出来,有三种情况,一是属于人类已知情况的诱因,二是分类错误的,三是标出的不符合以前的人的认知,可以进一步研究,甚至推动医学的发展。
比如已经有标签的太阳耀斑爆发图片,根据模型解释解释何处判断耀斑爆发,如果是以前未发现的地方,甚至可能反过来推动人类物理模型的发展。
参考
- 官方文献 “Why Should I Trust You?”: Explaining the Predictions of Any Classifier
- 官方源码 https://github.com/marcotcr/lime
- 其他源码使用示例 https://github.com/pytorch/captum/blob/master/tutorials/Image_and_Text_Classification_LIME.ipynb
- 英文阅读者 https://christophm.github.io/interpretable-ml-book/lime.html
- 中文阅读者 【论文阅读·2】”Why Should I Trust You?” Explaining the predictions of Any Classifier_JLothar的博客-CSDN博客
- 其他应用综述 医学影像处理的深度学习可解释性研究进展